Abstract
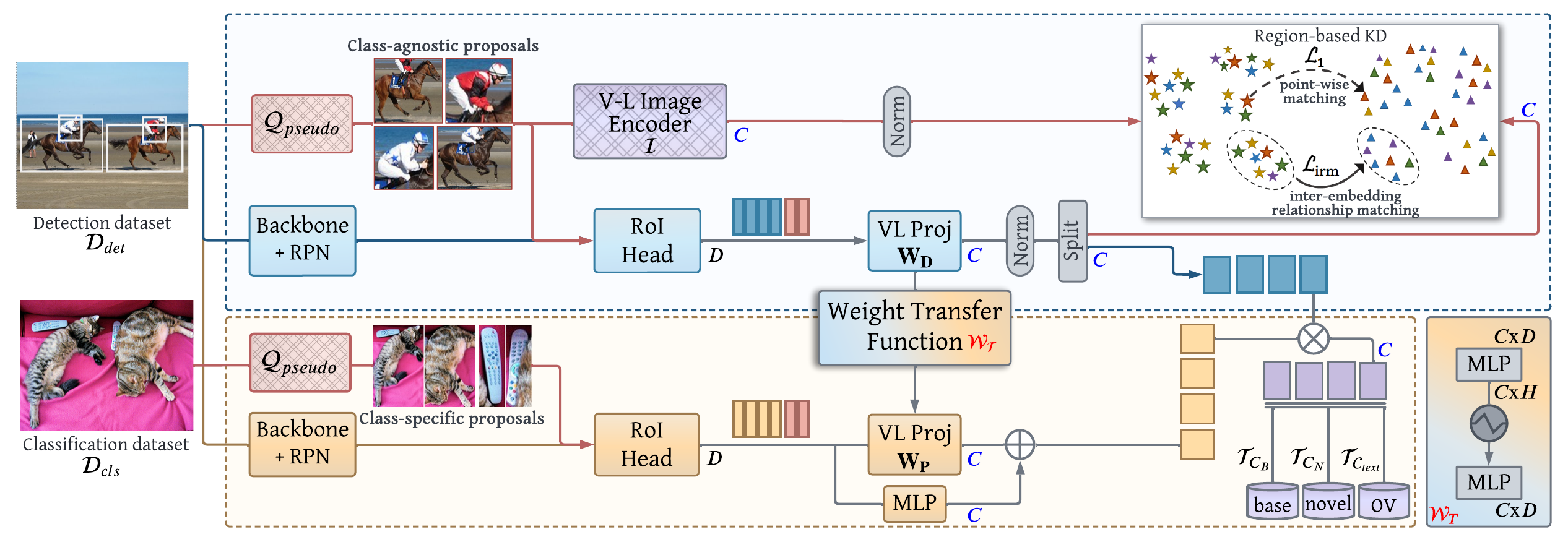
Existing open-vocabulary object detectors typically enlarge their vocabulary sizes by leveraging different forms of weak supervision. This helps generalize to novel objects at inference. Two popular forms of weak-supervision used in open-vocabulary detection (OVD) include pretrained CLIP model and image-level supervision. We note that both these modes of supervision are not optimally aligned for the detection task: CLIP is trained with image-text pairs and lacks precise localization of objects while the image-level supervision has been used with heuristics that do not accurately specify local object regions. In this work, we propose to address this problem by performing object-centric alignment of the language embeddings from the CLIP model. Furthermore, we visually ground the objects with only image-level supervision using a pseudo-labeling process that provides high-quality object proposals and helps expand the vocabulary during training. We establish a bridge between the above two object-alignment strategies via a novel weight transfer function that aggregates their complimentary strengths. In essence, the proposed model seeks to minimize the gap between object and image-centric representations in the OVD setting. On the COCO benchmark, our proposed approach achieves 36.6 AP50 on novel classes, an absolute 8.2 gain over the previous best performance. For LVIS, we surpass the state-of-the-art ViLD model by 5.0 mask AP for rare categories and 3.4 overall.
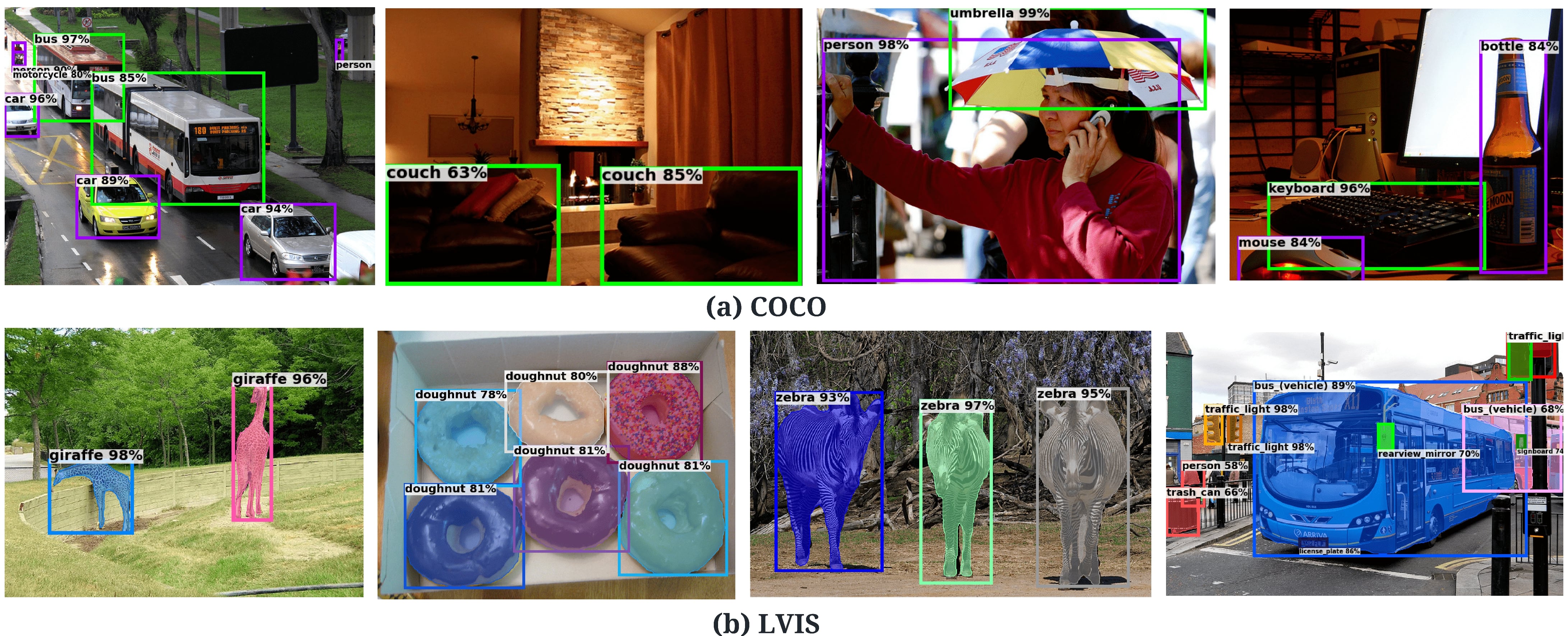
Qualitative Results (Open Vocabulary Setting)
For COCO, base and novel categories are shown in purple and green colors respectively.
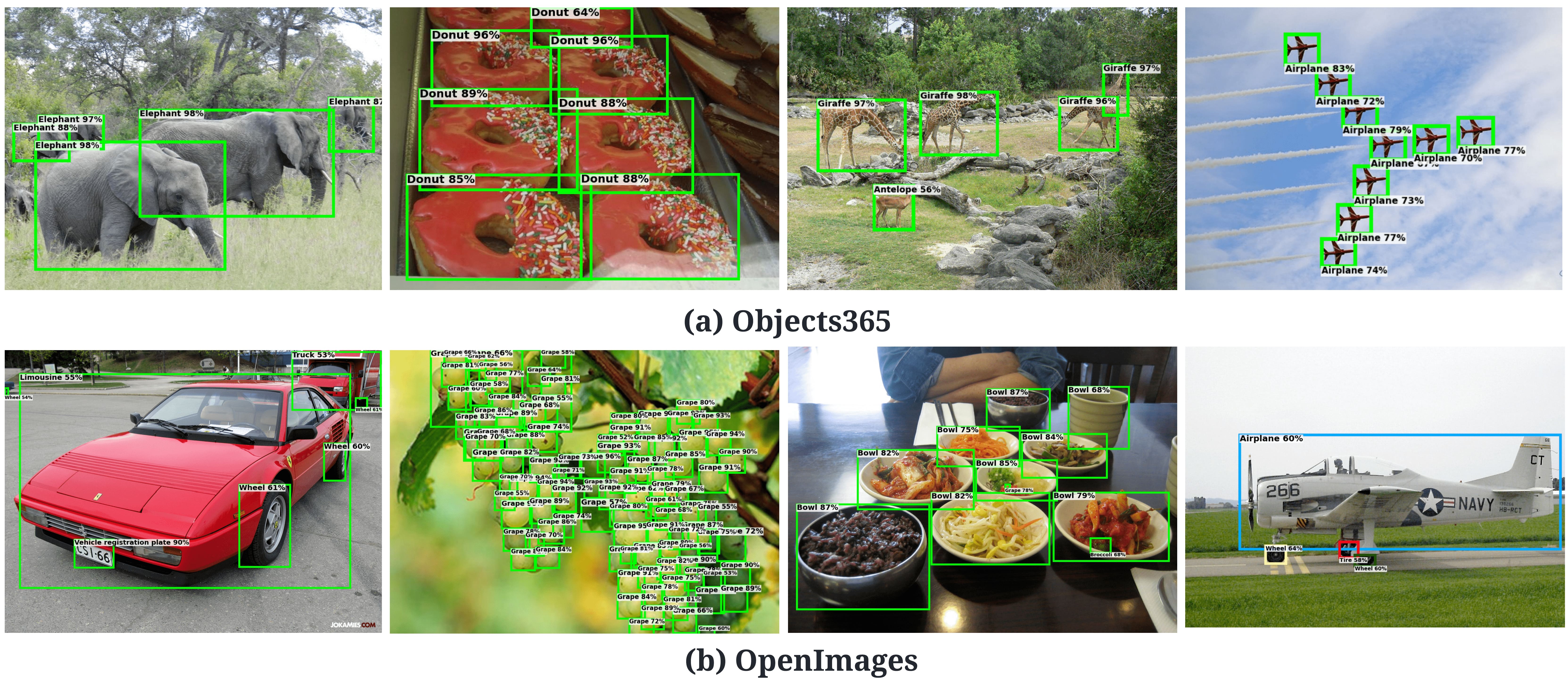
Qualitative Results (Cross Datasets transfer)
Model Zoo
New LVIS Baseline
Our Mask R-CNN based LVIS Baseline (mask_rcnn_R50FPN_CLIP_sigmoid) achieves 12.2 rare class and 20.9 overall AP and trains in only 4.5 hours on 8 A100 GPUs. We believe this could be a good baseline to be considered for the future research work in LVIS OVD setting.
| Name | APr | APc | APf | AP | Epochs |
|---|---|---|---|---|---|
| PromptDet Baseline | 7.4 | 17.2 | 26.1 | 19.0 | 12 |
| ViLD-text | 10.1 | 23.9 | 32.5 | 24.9 | 384 |
| Ours Baseline | 12.2 | 19.4 | 26.4 | 20.9 | 12 |
Open-vocabulary COCO
Effect of individual components in our method. Our weight transfer method provides complimentary gains from RKD and ILS, achieving superior results as compared to naively adding both components.
| Method | APnovel | APbase | AP | Download |
|---|---|---|---|---|
| Base-OVD-RCNN-C4 | 1.7 | 53.2 | 39.6 | model |
| COCO_OVD_Base_RKD | 21.2 | 54.7 | 45.9 | model |
| COCO_OVD_Base_PIS | 30.4 | 52.6 | 46.8 | model |
| COCO_OVD_RKD_PIS | 31.5 | 52.8 | 47.2 | model |
| COCO_OVD_RKD_PIS_WeightTransfer | 36.6 | 54.0 | 49.4 | model |
| COCO_OVD_RKD_PIS_WeightTransfer_8x | 36.9 | 56.6 | 51.5 | model |
Open-vocabulary LVIS
Effect of proposed components in our method on LVIS.
| Method | APr | APc | APf | AP | Download |
|---|---|---|---|---|---|
| mask_rcnn_R50FPN_CLIP_sigmoid | 12.2 | 19.4 | 26.4 | 20.9 | model |
| LVIS_OVD_Base_RKD | 15.2 | 20.2 | 27.3 | 22.1 | model |
| LVIS_OVD_Base_PIS | 17.0 | 21.2 | 26.1 | 22.4 | model |
| LVIS_OVD_RKD_PIS | 17.3 | 20.9 | 25.5 | 22.1 | model |
| LVIS_OVD_RKD_PIS_WeightTransfer | 17.1 | 21.4 | 26.7 | 22.8 | model |
| LVIS_OVD_RKD_PIS_WeightTransfer_8x | 21.1 | 25.0 | 29.1 | 25.9 | model |
Comparison with Existing OVOD Works
Open-vocabulary COCO
We compare our OVD results with previously established methods. †ViLD and our methods are trained for longer 8x schedule. ‡We train detic for another 1x for a fair comparison with our method. For ViLD, we use their unified model that trains ViLD-text and ViLD-Image together. For Detic, we report their best model.
| OVR-CNN | 22.8 | 46.0 | 39.9 |
| ViLD† | 27.6 | 59.5 | 51.3 |
| Detic | 27.8 | 47.1 | 45.0 |
| Detic‡ | 28.4 | 53.8 | 47.2 |
| Ours | 36.6 | 54.0 | 49.4 |
| Ours† | 36.9 | 56.6 | 52.5 |
Open-vocabulary LVIS
Comparison with prior work ViLD, using their unified model (ViLD-text + ViLD-Image).
| ViLD | 16.1 | 20.0 | 28.3 | 22.5 | 384 |
| Ours | 17.1 | 21.4 | 26.7 | 22.8 | 36 |
| Ours | 21.1 | 25.0 | 29.1 | 25.9 | 96 |
We show compare our method with Detic, by building on their strong LVIS baseline using CenterNetV2 detector.
| Box-Supervised | 16.3 | 31.0 | 35.4 | 30.0 |
| Detic (Image + Captions) | 24.6 | 32.5 | 35.6 | 32.4 |
| Ours | 25.2 | 33.4 | 35.8 | 32.9 |
TSNE Visualizations
t-SNE plots of CLIP and our detector region embeddings on COCO novel categories.

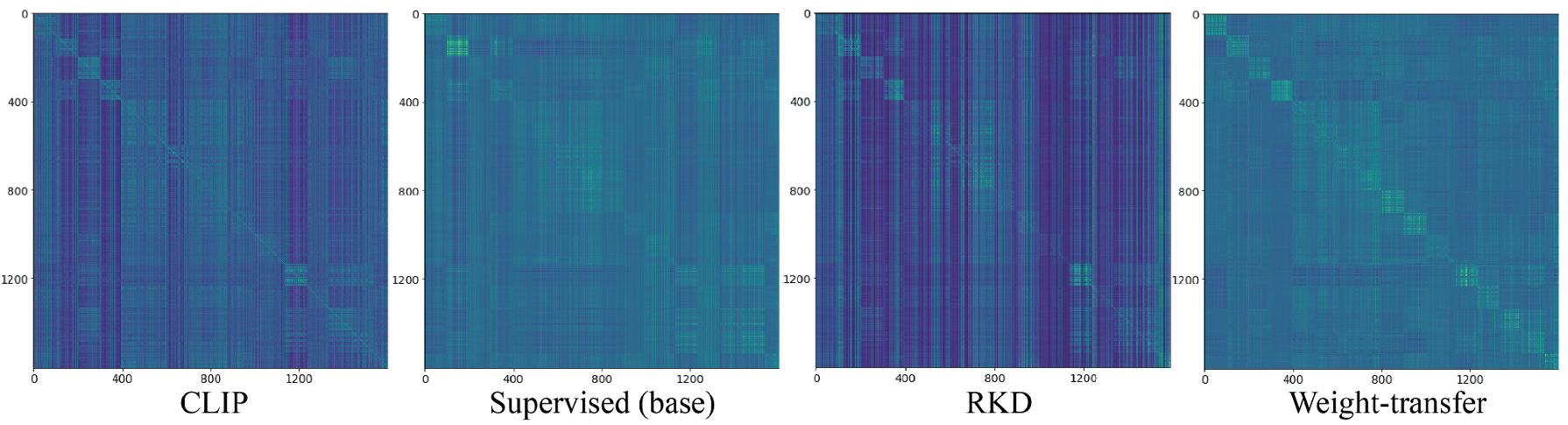
Region Embeddings Similarity Matrices
Plots of the Region Embeddings similarity matrices of COCO Novel categories by CLIP and our detector.
BibTeX
@inproceedings{Hanoona2022Bridging,
title={Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection},
author={Rasheed, Hanoona and Maaz, Muhammad and Khattak, Muhammad Uzair and Khan, Salman and Khan, Fahad Shahbaz},
booktitle={36th Conference on Neural Information Processing Systems (NIPS)},
year={2022}
}