|
I am an Ph.D. Computer Vision student at MBZUAI working under the supervision of Dr. Fahad and Dr. Salman. My research is focused on developing multi-modal understanding from vision and text to improve common-sense reasoning of machines and its applications in open-vocabulary and open-world object detection.. Email / CV / Google Scholar / GitHub / LinkedIn |

|
|
* denotes equal contribution co-authorship |
|
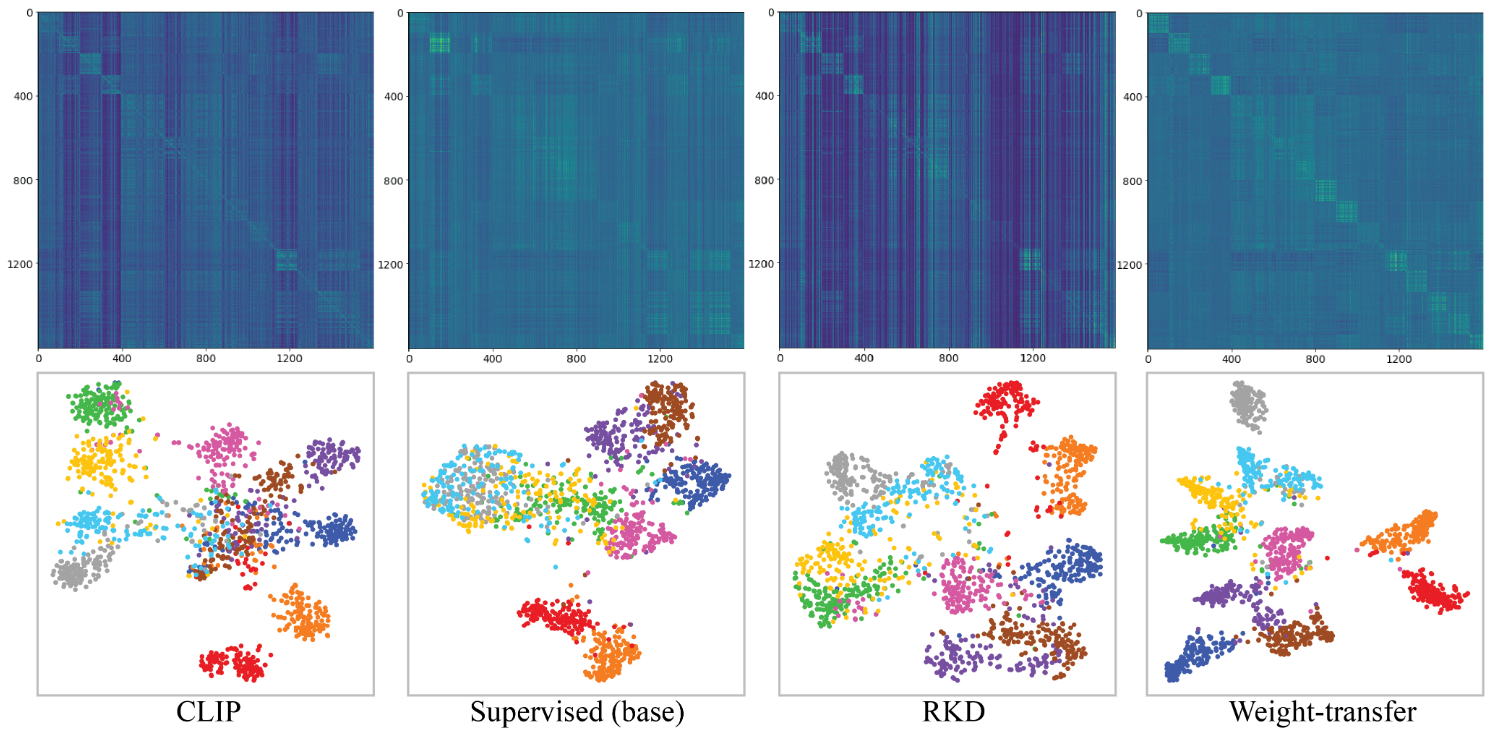
Hanoona Rasheed*, Muhammad Maaz*, Muhammad Uzair Khattak Salman Khan, Fahad Shahbaz Khan, NeurIPS, 2022 project page / arXiv / video In this work, we propose to solve the Open-vocabulary detection (OVD) problem using pretrained CLIP model, adapting it for object-centric local regions using region-based distillation and image-level weak supervision. Specifically, we propose to utilize high-quality class-agnostic and class-specific object proposals via the pretrained mulit-modal vision transformers (MViT). The class-agnostic proposals are used to distill region-specific information from CLIP and class-specific proposals allows us to visually ground large vocabularies. We also introduce a region-conditioned weight transfer method to get complementary benefits from both region-based distillation and image-level supervision. |
|
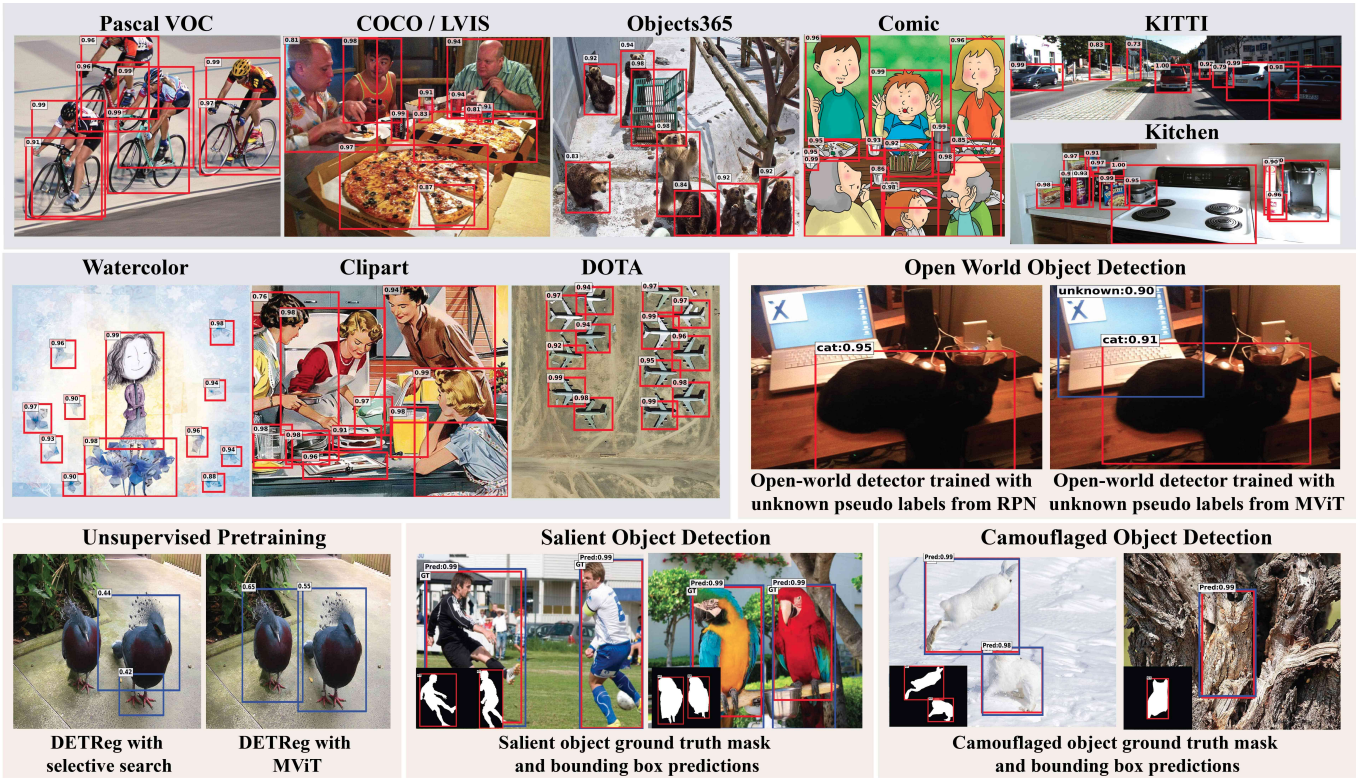
Muhammad Maaz*, Hanoona Rasheed*, Salman Khan, Fahad Shahbaz Khan, Rao Muhammad Anwer Ming-Hsuan Yang ECCV, 2022 project page / arXiv / video In this work, we explore the potential of the recent Multi-modal Vision Transformers (MViTs) for class-agnostic object detection. Our extensive experiments across various domains and novel objects show the state-of-the-art performance of MViTs to localize generic objects in images. We also develop an efficient and flexible MViT architecture using multi-scale feature processing and deformable self-attention that can adaptively generate proposals given a specific language query. |

|
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, Fahad Shahbaz Khan, Under Review, 2022 project page / arXiv In this work, we propose to learn prompts in both vision and language branches of pretrained CLIP for adapting it to different downstream tasks. Previous works only use prompting in either language or vision branch. We note that using prompting to adapt representations in a single branch of CLIP (language or vision) is sub-optimal since it does not allow the flexibility to dynamically adjust both representation spaces on a downstream task. To this end, we propose Multi-modal Prompt Learning (MaPLe) for both vision and language branches to improve alignment between the vision and language representations. Our design promotes strong coupling between the vision-language prompts to ensure mutual synergy and discourages learning independent uni-modal solutions. |
|
You've probably seen this website template before, thanks to Jon Barron. |